Privacy-Handbuch
Surfen… Passwörter & 2FA Bezahlen im Netz E-Mail (allgm) E-Mail (crypt) Chatten…
Tor… VPNs… DNS…
Daten schützen PC/Laptop OS Smartphones
|
|
|
Librewolf Mullvad Browser
Aus unterschiedlichen Gründen wird immer wieder empfohlen, die User-Agent Kennung zu modifizieren (faken). Linuxer und MacOS Nutzer sollen eine Fake für einen Google Chrome (Windows) verwenden, weil dieser Browser häufiger verwendet wird und man damit angeblich besser in der Masse untertaucht. Windows Nutzer sollen als ein Linux OS spoofen, um sich gegen Drive-by-Downloads von Malware zu schützen... u.a.m.
Es ist nahezu unmöglich, die User Agent Kennung eines Browsers plausibel zu faken. Eine unsachgemäße Änderung kann zu einem einzigartigen Gesamtbild führen, welches das Tracking enorm erleichtert und man erreicht das Gegenteil des Beabsichtigten.
Der ehemalige Anonymitätstest von JonDonym (jetzt nicht mehr online) entlarvte viele Fehler und wurde genutzt, um diesen Artikel zu schreiben. Aktuell könne man mit CreepJS testen.
HTTP Header: Die einzelnen Browser sind durch individuelle Headerzeilen und -reihenfolge im HTTP-Request beim Aufruf einer Webseite unterscheidbar. Eine Tarnung mit dem User-Agent eines anderen Browsers ist oft leicht als Fake zu identifizieren. Viele Add-ons zum Spoofen der User Agent Kennung machen diesen Fehler.
Das Add-on User-Agent Overrider (Version 0.2.5.1) sollte im Test einen Internet Explorer 9.0 für Win64 faken (MSIE 9.0). Die Header Signatur entlarvt den Browser jedoch als einen Firefox, der sich als IE tarnen will.Das Add-on Random Agent Spoofer (Version 0.9.5.2) sollte im Test einen Google Chrome Browser 41.0 für Win64 faken. Die Header Signatur entlarvt den Browser ebenfalls als Firefox, der sich tarnen will.

Firefox Release Versionen und Firefox ESR Versionen unterscheiden sich nicht nur in der Version in der User-Agent Kennung sondern auch in anderen Eigenschaften:- Firefox 68.x ESR und Firefox 72+ unterscheiden sich im HTTP-Accept-Header:
Firefox 68: ...application/xml;q=0.9,*/*;q=0.8
Firefox 72: ...application/xml;q=0.9, image/webp,*/*;q=0.8 - Firefox 45.x ESR und Firefox 47+ unterscheiden sich im TLS Handshake, weil ab Version 47 der Cipher "ChaCha20-Poly1350" für die SSL/TLS-Verschlüsslung unterstützt wird und beim Handshake angeboten wird.
- Firefox 68.x ESR und Firefox 72+ unterscheiden sich im HTTP-Accept-Header:
Firefox 68: ...application/xml;q=0.9,*/*;q=0.8
Javascript: Das Add-on User Agent Platform Spoofer macht aus einem Firefox für Windows einen Firefox für Linux und umgekehrt, um die automatische Installation von Malware im Drive by Download zu erschwerden.
Auch hier ist der Fake nicht vollständig, wie ein kurzer Test unter Linux zeigt. Mit Javascript kann der genutzte Browsertyp und Betriebssystem ermittelt werden:User-Agent via HTTP Header: Mozilla/5.0 (Windows NT 10.0; Win64; x64.... Browsertyp via Javascript: Mozilla/5.0 (X11) 20100101/... - CSS Attribute: Durch unterschiedliche Font Rendering Bibliotheken ergeben sich Abweichungen bei CSS Attributen, die mit Javascript ausgelesen werden können. Anhand des CSS-Attributes "line-height" kann man zum Beispiel bei Verwendung hoch- und tiefgestellter Zeichen Schlussfolgerungen über das Betriebssystem ziehen. Es ergeben sich unterschiedliche Werte bei gleichem HTML Code, beispielsweise 19px für Linux, 19.5167px für MacOS und 19.2px oder 20px für Windows.
- Der TorBrowser fakt auch die bevorzugte Sprache des Browsers und verwendet "en-US" für alle Lokalisierungen, um die Anonmymitätsgruppe zu vergrößern. Für einen normalen Firefox ohne Patches von TorProject.org ist das nicht empfehlenswert.
- Es ist einfach plausibler, wenn man mit einer deutschen IP-Adresse beim Besuch einer deutschsprachigen Webseite auch einen deutschen Browser verwendet.
- Mit Hilfe der "JavaScript Localisation API" können diese Fakes bei aktivem Javascript entlarvt werden, wenn man keine zusätzlichen Schutzmaßnahmen implementiert.
Mit der Javascript Funktion "Date.toLocaleFormat()" kann man Datums- und Zeitangaben in die bevorzuge Desktop(!) Lokalisierung des Nutzers umrechnen lassen und das Ergebnis auswerten:
Deutsche Ausgabe eines Datums mit Zeitangabe: 01.02.2013 13:00
US-Englische Ausgabe des Datums (civilian): 2/1/2013 1:00 PM
US-Englische Ausgabe (military, science): 2013-02-01, 1300 hours Man kann ein US-englisches Verhalten für Javascript Konvertierungen erzwingen, indem man eine neue Variable unter "about:config" anlegt: javascript.use_us_english_locale = true - Durch Auswertung der Keyboard Events könnte ein Angreifer die Lokalisierung der Tastatur ermitteln. Die Verwendung eines deutschen Browsers ist in Kombination mit einer deutschen Tastatur ebenfalls plausibler.
- Der Browser hängt in viele Dingen von Bibliotheken des Betriebssystems ab. Durch Auswertung einige Seltsamkeiten lässt sich das real verwendete Betriebssystem teilweise identifizieren oder zumindest ein User-Agent Fake entlarven.
Ein Beispiel OS-spezifische Seltsamkeiten ist das Ergebnis der folgenden Javascript Berechnung:
Math.tan(-1e300) = -4.987183803371025 (Windows)
Math.tan(-1e300) = -1.4214488238747245 (Linux, iOS) - Plug-ins wie das Java Plug-in verraten in der Regel das verwendete Betriebssystem und Browser und können keinen Fake konfigurieren.
Schlussfolgerung
Es ist nahezu unmöglich, die User-Agent Kennung von Firefox plausibel in allen Punkten zu faken. Ein unvollständiger Fake-Versuch ist aber ein gutes Identifizierungsmerkmal für Trackingdienste, da man sich von der großen Masse der Surfer stärker unterscheidet.
Paywalls umgehen als GoogleBot oder BingBot
Viele Online Medien haben in den letzten Jahren eine Paywall eingeführt, um Artikel nur für Premium Nutzer zur Verfügung zu stellen. Gleichzeitig möchten sie aber, dass diese Artikel weiterhin von Suchmaschinen in den Index aufgenommen werden, damit Leser angelockt werden. Um das zu ermöglichen, bauen sie eine Hintertür ein. Wenn die Seite mit der User-Agent Kennung des Crawlers einer Suchmaschine wie GoogleBot abgerufen werden, dann kann man oft (aber nicht immer)…
Das ist kein Bug sondern ein Feature, das die Webmaster der Online Medien extra eingebaut haben und dabei die Hinweise von Google zur Verifikation des Bots ignorieren (zu kompliziert?)
Die User-Agent Kennung vom allgm. Google Bot ist:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)Die User-Agent Kennung vom Bing Bot ist:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) Chrome/W.X.Y.Z Safari/537.36(Der Trick funktioniert bei Berliner Zeitung und NZZ aber nicht bei Heise, Spiegel, FAZ oder Bild.)
Es ist aber keine gute Idee, die Googlebot Kennung generell zu verwenden. Dann bekommt man Probleme bei einigen Webseiten und hat außerdem einen eindeutigen Fingerprint.
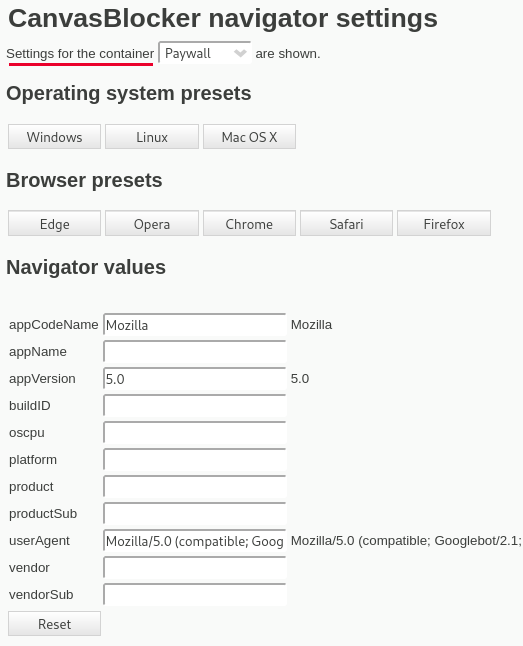
Das Add-on CanvasBlocker kann in verschiedenen userContext Containern den User-Agent faken. Man erstellt sich einen neuen userContext (z.B. "Paywall") oder verwendet einen vorhanden.
In den Einstellungen von CanvasBlocker auf dem Reiter "APIs" aktiviert man die Navigator API:
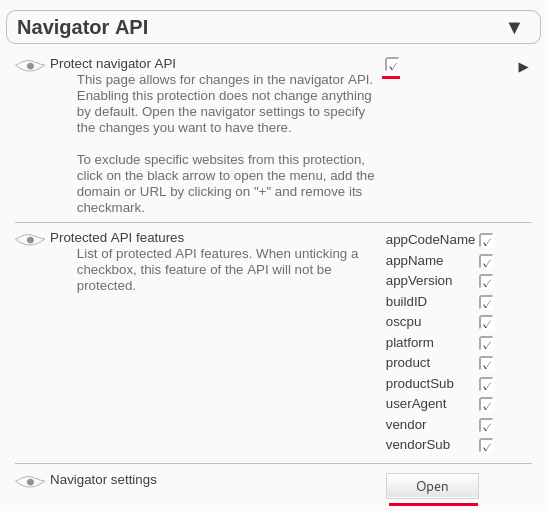
Ein Klick auf den Open-Button öffnet die Navigator Settings. Hier wählt man zuerst den userContext, für den man den Fake konfiguieren möchte und stellt dann den User-Agent Fake für GoogleBot ein:
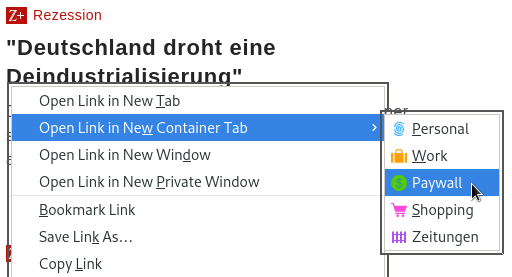
Wenn man auf eine Paywall trifft und kann man die Seite im userContext "Paywall" öffnen (z.B. mit einem Rechts-Klick auf den Link) und hat dann öfters die Möglichkeit, den Artikel zu lesen.
Spurenarm Surfen
- Mullvad Browser
- Mozilla Firefox
- Schnell-Konfig.
- Suchmaschinen
- Trackingschutz
- Firefox Sicherheit
- Firefox Features
- Firefox user.js
- Snakeoil
- Librewolf Browser
PW/2FA… E-Mails… Chatten…
Tor… VPN… DNS…
Daten schützen PC/Laptop OS Smartphones
|
|
|